SchemaBrain으로 ERD와 SQL 튜닝을 한 번에 잡는 방법
※ 이 게시물은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다.
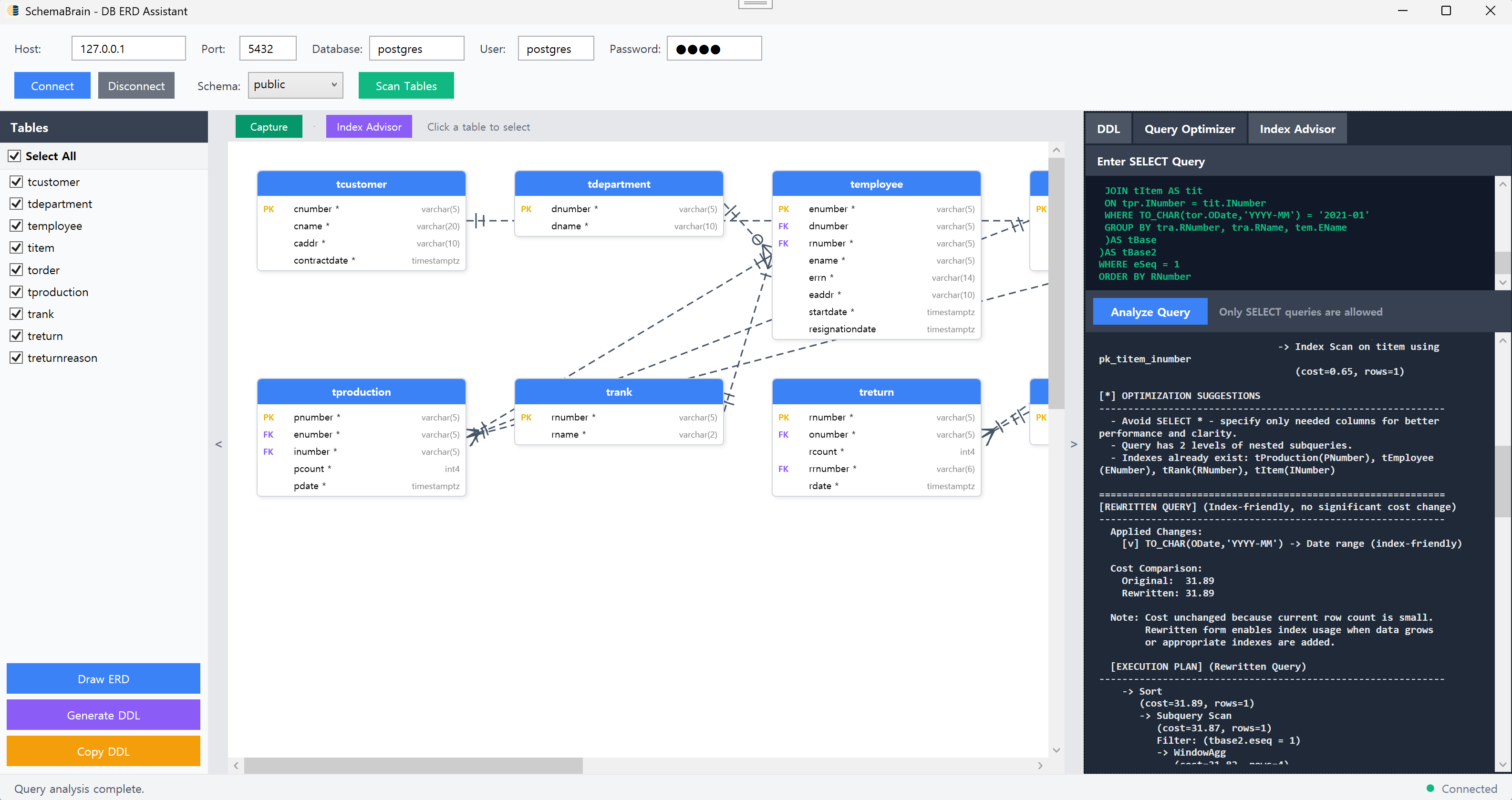
SchemaBrain is a desktop application I pulled back into my toolkit after a reporting database suddenly multiplied from 18 to 58 tables in two sprints. 데이터베이스가 두 번의 스프린트 동안 18개에서 58개 테이블로 폭증했을 때 다시 꺼낸 데스크톱 애플리케이션이 SchemaBrain이다.
The tool merges ERD visualization, query plan digging, and index coaching so I can stop hopping between pgAdmin diagrams and handwritten EXPLAIN notes. 이 도구는 ERD 시각화, 실행 계획 파기, 인덱스 코칭을 합쳐 pgAdmin 다이어그램과 손으로 적은 EXPLAIN 노트를 오가던 흐름을 끊어주었다.
Why I revisited SchemaBrain
왜 다시 SchemaBrain을 꺼냈는지
SchemaBrain earned another look because the new analytics squad kept slipping functions onto indexed columns and wondering why latency doubled. 새 분석 스쿼드가 인덱스 컬럼 위에 함수를 계속 얹어 놓고 지연이 두 배로 뛴 이유를 묻길래 SchemaBrain을 다시 열었다.
Its ERD canvas let me reverse-engineer the entire schema straight from the VPN tunnel without exporting a single .pgerd file.
ERD 캔버스가 VPN 터널 안에서 스키마 전체를 역설계하게 해줘서 별도의 .pgerd 파일을 내보낼 필요가 없어졌다.
Dragging tables around felt closer to a whiteboard session than a rigid modeling suite, which made stakeholder reviews a lot faster. 테이블을 드래그하는 감각이 딱딱한 모델링 도구보다 화이트보드 회의에 가깝게 느껴져서 이해관계자 검토가 훨씬 빨랐다.
Automatic ERD builder checkpoints
자동 ERD 빌더 점검 메모
SchemaBrain connects to PostgreSQL and reverse-generates diagrams with PK/FK detection that respected naming conventions like sales.order_id.
SchemaBrain은 PostgreSQL에 붙어 sales.order_id 같은 네이밍 규칙을 지키면서 PK/FK를 감지한 다이어그램을 역생성한다.
- Connect to PostgreSQL instances without juggling ODBC DSNs or service files. ODBC DSN이나 서비스 파일을 만지작거리지 않고도 PostgreSQL 인스턴스에 바로 붙을 수 있다.
- Rearrange and group tables on the canvas, then export high-res PNGs for review decks. 캔버스 위에서 테이블을 재배치하고 그룹화한 뒤 검토 자료에 넣을 고해상도 PNG로 내보낼 수 있다.
- Zooming and snapping behave predictably enough that junior devs can document flows themselves. 줌과 스냅 동작이 예상대로라 주니어 개발자가 직접 플로우를 기록해도 어긋나지 않는다.
The ERD builder also highlighted missing foreign keys by coloring edges orange, so I could trace accidental cross-schema joins in seconds. ERD 빌더는 엣지를 주황색으로 칠해 누락된 외래키를 강조해 줘서 스키마를 넘나드는 조인이 우연히 생겼는지 몇 초 만에 추적할 수 있었다.
Query analyzer reality check
쿼리 분석기 실전 점검
SchemaBrain parses SQL, pulls the execution plan, and lists anti-patterns such as ORDER BY without LIMIT or nested subqueries that explode cost. SchemaBrain은 SQL을 파싱하고 실행 계획을 끌어와 LIMIT 없는 ORDER BY나 비용을 키우는 중첩 서브쿼리 같은 안티패턴을 나열한다.
I liked that every warning came with human-readable text, so I could paste snippets straight into the squad chat without rephrasing them. 모든 경고가 사람이 읽을 텍스트로 붙어 있어 재작성 없이 바로 스쿼드 채널에 붙여넣을 수 있다는 점이 마음에 들었다.

When it spotted functions on indexed columns, it even reminded us that LOWER(email) breaks index usage in PostgreSQL unless we maintain a functional index.
인덱스 컬럼에 함수를 올린 걸 발견하면 PostgreSQL에서는 함수 기반 인덱스를 따로 두지 않으면 LOWER(email)이 인덱스 사용을 깨버린다고 친절히 알려준다.
SchemaBrain also flags ORDER clauses that scan entire tables because engineers forgot to pair them with LIMIT, a pattern we keep slipping back into. SchemaBrain은 LIMIT을 붙이지 않아 전체 테이블을 긁어버리는 ORDER 절도 표시해서 자꾸 반복되는 실수를 잡아낸다.
Index advisor in action
인덱스 어드바이저 실전 적용
SchemaBrain reads pg_catalog, pg_stats, pg_index, and pg_stat_user_tables to figure out missing FK indexes or stale statistics.
SchemaBrain은 pg_catalog, pg_stats, pg_index, pg_stat_user_tables를 읽어 누락된 외래키 인덱스나 낡은 통계를 찾아낸다.
It suggested B-Tree indexes for date range filters, GIN for JSONB search, and even partial indexes for NULL-heavy audit columns. 이 도구는 날짜 범위 필터에 B-Tree, JSONB 검색에는 GIN, NULL이 많은 감시 컬럼에는 부분 인덱스를 제안했다.
Each recommendation ships with executable SQL plus a sentence explaining the row estimate that triggered it, so code reviews stay civil. 각 추천은 실행 가능한 SQL과 해당 제안을 촉발한 행 추정치 설명을 붙여주니 코드 리뷰가 한결 편해졌다.
It even nudged us to rerun ANALYZE on tables where n_mod_since_analyze went past our tolerance, which we usually miss until latency spikes.
n_mod_since_analyze가 허용치를 넘은 테이블에 ANALYZE를 다시 돌리라고 알려줘서, 평소엔 지연이 터져야 알던 상태를 미리 정리했다.
Performance insight cues
성능 인사이트 큐
Rather than dumping low-level metrics, SchemaBrain frames guidance like “this FK join will fall back to sequential scans without an index.” SchemaBrain은 저수준 지표를 던지는 대신 “이 외래키 조인은 인덱스가 없으면 순차 스캔으로 떨어진다”처럼 맥락 있는 조언으로 안내한다.
Those sentences made it easier to turn insights into Jira tasks because PMs could understand why a change mattered without reading VACUUM docs. 그 문장 덕분에 PM이 VACUUM 문서를 읽지 않아도 변경 이유를 이해해 Jira 태스크로 옮기기 쉬웠다.
It also surfaced planner hints on why a WHERE clause prevented index usage, so we rewrote a couple of conditions to align with statistics. WHERE 절 때문에 인덱스 사용이 막힌 이유를 플래너 힌트로 보여줘서 통계에 맞게 조건 두 개를 갈아엎었다.
Portable Windows deployment
휴대용 윈도우 배포 경험
SchemaBrain ships as a portable Windows executable, so I unzipped it into C:\Tools\SchemaBrain and synced settings via OneDrive.
SchemaBrain은 휴대용 윈도우 실행 파일로 배포돼 C:\Tools\SchemaBrain에 풀고 OneDrive로 설정을 동기화할 수 있었다.
No installer means fewer security tickets, and I can hand QA a copy without admin rights, which matters on client laptops. 설치 프로그램이 없으니 보안 티켓이 줄고 관리자 권한 없이 QA에게 복사본을 건넬 수 있어 고객사 노트북에서 특히 편하다.
Tech stack check
기술 스택 점검
The UI leans on WPF with MVVM bindings, so panels stay responsive even when ERD canvases get busy. UI는 MVVM 바인딩을 갖춘 WPF라서 ERD 캔버스가 복잡해져도 패널 반응이 끊기지 않는다.
A custom graph layout engine arranges tables with a force-directed feel, which beats the rigid grids I used to tolerate. 커스텀 그래프 레이아웃 엔진이 힘 기반 배치를 사용해 이전에 참고하던 격자보다 자연스럽게 테이블을 정렬한다.
Database access relies on an Npgsql metadata scanner, and the analysis layer sits on PostgreSQL EXPLAIN plus a small rules engine. 데이터베이스 접근은 Npgsql 메타데이터 스캐너에 기대고 분석 레이어는 PostgreSQL EXPLAIN과 소형 룰 엔진 위에 놓여 있다.
Download and licensing
다운로드와 라이선스 안내
Repository: https://github.com/SevenfingersStudio/SchemaBrain
저장소: https://github.com/SevenfingersStudio/SchemaBrain
Windows portable edition runs without installation, so unzip and launch the executable immediately. 윈도우 포터블 에디션은 설치 없이 실행되므로 압축을 풀고 바로 실행 파일을 띄우면 된다.
Operator field notes
운영자 실전 노트
- SchemaBrain caught a cross-schema FK without an index, saving me from a production outage during end-of-month billing. SchemaBrain이 스키마를 넘나드는 인덱스 없는 외래키를 잡아줘서 월말 청구 기간의 장애를 피했다.
- Query analyzer output became the default code-review checklist, so juniors stopped merging ORDER BY clauses without LIMIT. 쿼리 분석기 결과를 코드 리뷰 체크리스트 기본값으로 삼으니 주니어가 LIMIT 없는 ORDER BY를 머지하지 않게 됐다.
- I now export ERD PNGs before every stakeholder briefing, which shortens meetings because everyone already saw the layout. 이해관계자 브리핑 전에 ERD PNG를 뽑아 돌리기 시작해 회의가 레이아웃 설명 없이 빨리 끝난다.
FAQ
자주 묻는 질문
Q. How accurate are the index recommendations when schemas keep changing? Q. 스키마가 계속 바뀌어도 인덱스 추천이 정확한가요?
SchemaBrain compares last_analyze timestamps and row estimates on each run, so stale hints rarely survive more than a day in my workflow.
SchemaBrain은 실행 때마다 last_analyze 타임스탬프와 행 추정치를 비교하므로 내 워크플로에서 하루 이상 묵은 힌트가 남는 일이 거의 없다.
Q. Can I trust the query analyzer over manual EXPLAIN in psql? Q. psql에서 직접 EXPLAIN을 보는 것보다 쿼리 분석기를 믿어도 되나요?
I still open psql for edge cases, but SchemaBrain surfaces the same EXPLAIN plan plus narrative text, so 90% of reviews stay inside the app. 극단적인 케이스는 여전히 psql에서 보지만 SchemaBrain이 동일한 EXPLAIN 계획과 설명 텍스트를 함께 보여줘 리뷰의 90%는 앱 안에서 끝낸다.